Índice
¿Que es un índice?
El índice de una base de datos es una es una estructura de datos que mejora la velocidad de las operaciones, por medio de identificador único de cada fila de una tabla, permitiendo un rápido acceso a los registros de una tabla en una base de datos. Al aumentar drásticamente la velocidad de acceso, se suelen usar, sobre aquellos campos sobre los cuales se hacen frecuentes búsquedas.
El índice tiene un funcionamiento similar al índice de un libro, guardando parejas de elementos: el elemento que se desea indexar y su posición en la base de datos. Para buscar un elemento que esté indexado, sólo hay que buscar en el índice dicho elemento para, una vez encontrado, devolver el registro que se encuentre en la posición marcada por el índice.
El espacio en disco requerido para almacenar el índice es típicamente menor que el espacio de almacenamiento de la tabla (puesto que los índices generalmente contienen solamente los campos clave de acuerdo con los que la tabla será ordenada, y excluyen el resto de los detalles de la tabla), lo que da la posibilidad de almacenar en memoria los índices de tablas que no cabrían en ella.
Organizaciones de los ìndice
Los índices
pueden tener organización ordenados y directos.
ORDENADOS:
Están ordenados físicamente según el valor de la clave k.
DIRECTOS:
Están ordenados según una función hash sobre la clave k.
Tipos de Ìndice
Tipos de índices de un solo nivel:
• Índices primarios:
El archivo esta construido sobre un archivo ordenado, sobre un campo clave de ordenamiento (Dispersos,Densos).

• Índices de agrupamiento:
El indice esta construido sobre un archivo. Sobre un campo no clave de ordenamiento.


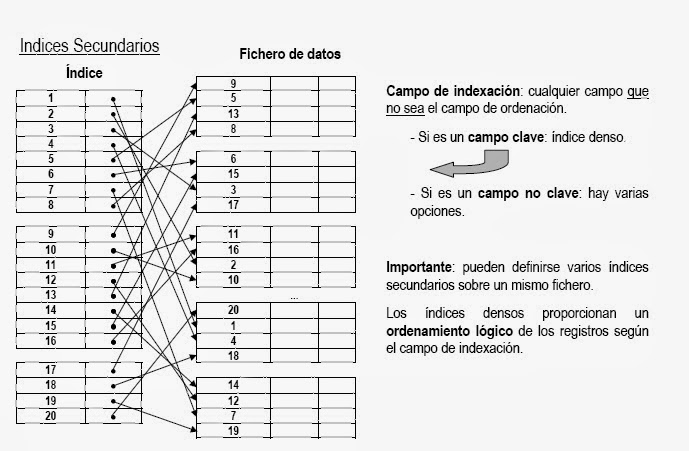
• Índices secundarios:
El indice esta construido sobre un archivo no ordenado o sobre un campo que no es clave de ordenamiento.

Cuadro comparativo
|
Tipo
de índice
|
AI
|
AD
|
|
PRIMARIO
|
Campo Clave
|
SO sobre la Clave
|
|
AGRUPADO
|
Campo no Clave
|
SO sobre el atributo no clave del índice
|
|
SECUNDARIO
|
Cualquiera
|
No esta ordenado
|
Indice por excelencia de la base de datos:
- Arboles B: En las ciencias de la computación, los árboles-B o B-árboles son estructuras de datos de árbol que se encuentran comúnmente en las implementaciones de bases de datos y sistemas de archivos. Son árboles balanceados de búsqueda en los cuales cada nodo puede poseer más de dos hijos. Los árboles B mantienen los datos ordenados y las inserciones y eliminaciones se realizan en tiempo logarítmico amortizado. Cada celda apunta al archivo de datos no se usa para indices.

- Arboles B+: En ciencias de la computación, unárbol B+ es un tipo de estructura de datos de árbol, representa una colección de datos ordenados de manera que se permite una inserción y borrado eficientes de elementos. Es un índice, multinivel, dinámico, con un límite máximo y mínimo en el número de claves por nodo. Un árbol B+ es una variación de un árbol B.En un árbol B+, toda la información se guarda en las hojas. Los nodos internos sólo contienen claves y punteros. Todas las hojas se encuentran en el mismo nivel, que corresponde al más bajo. Los nodos hoja se encuentran unidos entre sí como una lista enlazada para permitir búsqueda secuencial.Son mas fáciles de mantener.

Indice Bitmap
Están asociados con los valores de los registros .Crea arreglo de bit. Donde prende el valor que corresponde al arreglo.
Creación de Indices
Las siguientes tareas forman parte de la estrategia recomendada para crear índices:
- Diseñar el índice.El diseño de índices es una tarea crítica. El diseño de índices incluye la determinación de las columnas que se utilizarán, la selección del tipo de índice (por ejemplo, agrupado o no agrupado), la selección de opciones de índice adecuadas y la determinación de grupos de archivos o de la ubicación de esquemas de partición. Para obtener más información, vea Diseñar índices.
- Determinar el mejor método de creación. Los índices se crean de las siguientes maneras:
- Definiendo una restricción PRIMARY KEY o UNIQUE en una columna mediante CREATE TABLE o ALTER TABLESQL Server Database Engine (Motor de base de datos de SQL Server) crea automáticamente un índice único para hacer cumplir los requisitos de unicidad de una restricción PRIMARY KEY o UNIQUE. De forma predeterminada se crea un índice clúster único para hacer cumplir una restricción PRIMARY KEY, a menos que ya exista un índice clúster en la tabla o que usted especifique un índice no clúster único. De forma predeterminada se crea un índice único no clúster para hacer cumplir una restricción UNIQUE a menos que se especifique de explícitamente un índice clúster único y no exista un índice clúster en la tabla.También se pueden especificar las opciones de índice, la ubicación del índice, el grupo de archivos o el esquema de la partición.Un índice creado como parte de una restricción PRIMARY KEY o UNIQUE recibe automáticamente el mismo nombre que la restricción. Para obtener más información, vea Restricciones PRIMARY KEY yRestricciones UNIQUE.
- Creando un índice independiente de una restricción utilizando la instrucción CREATE INDEX , o el cuadro de diálogo Nuevo índice en el Explorador de objetos de SQL Server Management StudioDebe especificar el nombre del índice, de la tabla y de las columnas a las que se aplica el índice. También se pueden especificar las opciones de índice, la ubicación del índice, el grupo de archivos o el esquema de la partición. De forma predeterminada, se crea un índice que no es único y no está agrupado si no se especifican las opciones únicas o agrupadas. Para crear un índice filtrado, use la cláusula opcional WHERE. Para obtener más información, vea Directrices generales para diseñar índices filtrados.
- Crear el índice.Un factor importante que debe tenerse en cuenta es si el índice se creará en una tabla vacía o en una tabla con datos. La creación de un índice en una tabla vacía no tiene implicaciones de rendimiento en el momento de creación del índice; sin embargo, el rendimiento se verá afectado cuando se agreguen los datos a la tabla.La creación de índices en tablas grandes debe planearse con cuidado para que el rendimiento de la base de datos no se vea afectado. La mejor manera de crear índices en tablas de gran tamaño es empezar con el índice clúster y, a continuación, generar los índices no clúster. Considere la posibilidad de establecer la opción ONLINE en ON cuando cree índices en tablas existentes. Cuando se establece en ON, los bloqueos a largo plazo no se retienen, lo que permite que continúen consultas o actualizaciones a la tabla subyacente. Para obtener más información, vea Realizar operaciones de índices en línea.
Iraima Rodrìguez
Muy buen material, aprovechaste la información publicada en la web
ResponderBorrarAmplia un poco la información de indices bitmap
también debes definir previamente que son indices densos y dispersos
Coloca también la estructura de la instruccion en SQL para crear indices